IO,英文全称是Input/Output,翻译过来就是输入/输出。平时我们听得挺多,就是什么磁盘IO,网络IO。那IO到底是什么呢?
从计算机结构定义I/O
冯诺依曼结构将计算机分为5个部分:运算器,控制器,存储器,输入设备,输出设备
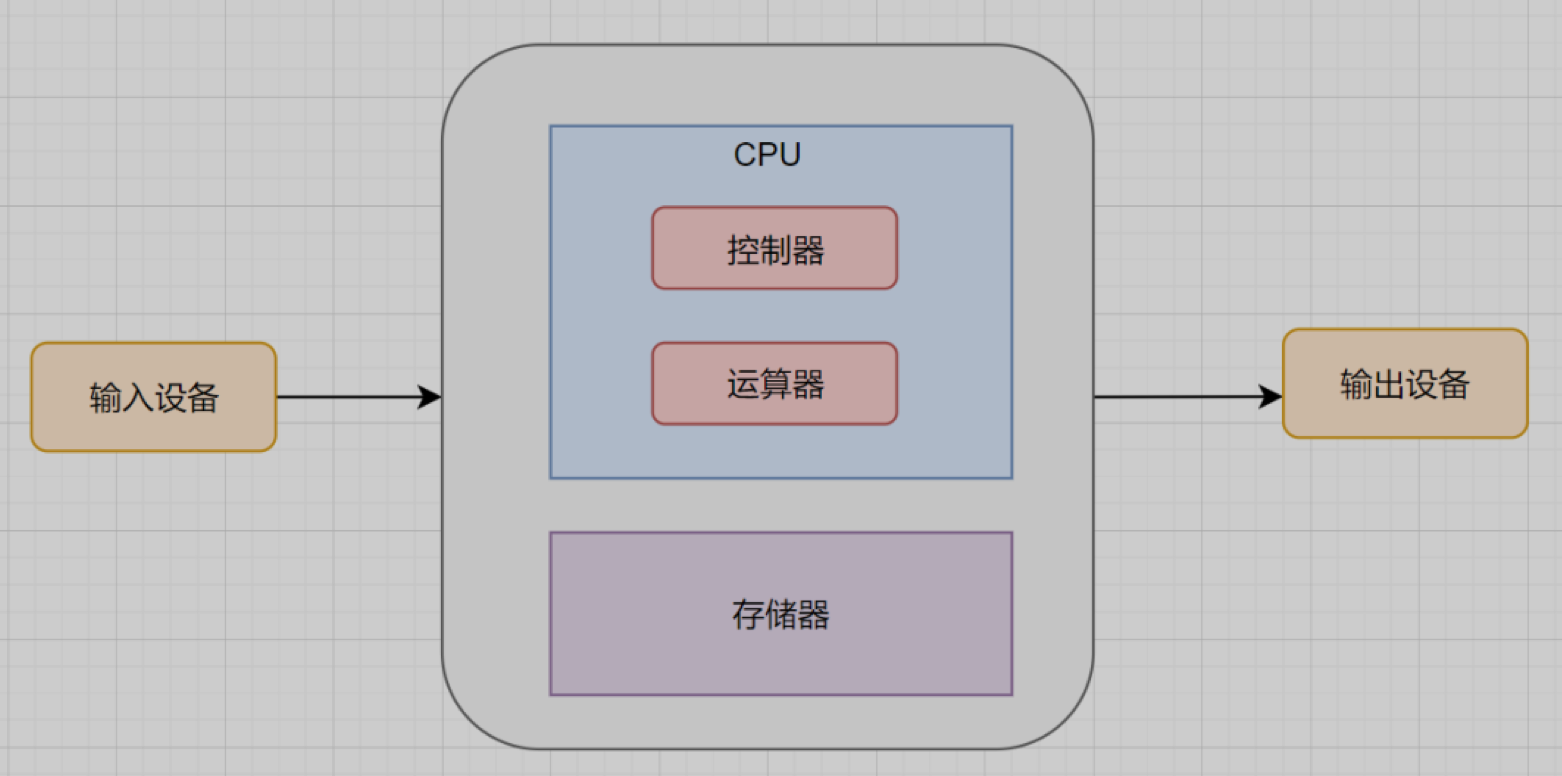
从计算机架构中看I/O就是:涉及计算机核心与其他设备间数据迁移的过程,就是IO。就是从磁盘读取数据到内存,这算一次输入,对应的,将内存中的数据写入磁盘,就算输出。这就是IO的本质。
从操作系统定义I/O
分清用户空间和内核空间
内核空间是操作系统内核访问的区域,是受保护的空间,而用户空间是应用程序访问的内存区域
真正执行IO的是在内核空间
我们应用程序是跑在用户空间的,它不存在实质的IO过程,真正的IO是在操作系统执行的。即应用程序的IO操作分为两种动作:IO调用和IO执行。IO调用是由进程(应用程序的运行态)发起,而IO执行是操作系统内核的工作。此时所说的IO是应用程序对操作系统IO功能的一次触发,即IO调用。
操作系统的一次IO过程
IO调用:应用程序进程向操作系统内核发起调用。
IO执行:操作系统完成IO操作
操作系统完成IO操作还包括两个步骤
准备数据阶段:内核等待I/O设备准备好数据
拷贝数据阶段:将数据从内核缓冲区拷贝到用户进程缓冲区
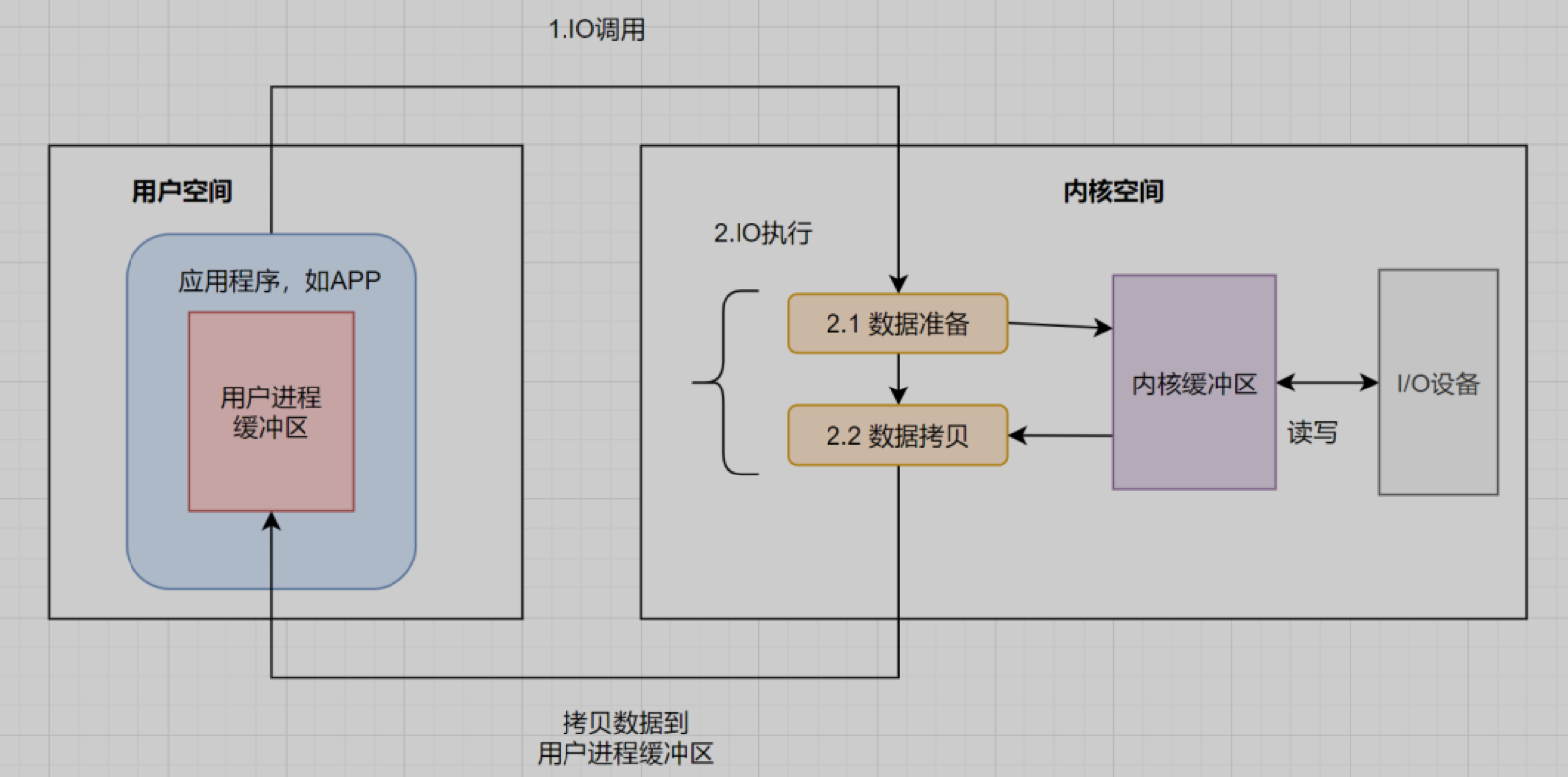
其实IO就是把进程的内部数据转移到外部设备,或者把外部设备的数据迁移到进程内部。外部设备一般指硬盘、socket通讯的网卡。一个完整的IO过程包括以下几个步骤:
- 应用程序进程向操作系统发起IO调用请求
- 操作系统准备数据,把IO外部设备的数据,加载到内核缓冲区
- 操作系统拷贝数据,即将内核缓冲区的数据,拷贝到用户进程缓冲区
阻塞I/O
应用程序的进程发起IO调用,但是如果内核的数据还没准备好的话,那应用程序进程就一直在阻塞等待,一直等到内核数据准备好了,从内核拷贝到用户空间,才返回成功提示,此次IO操作,称之为阻塞IO。
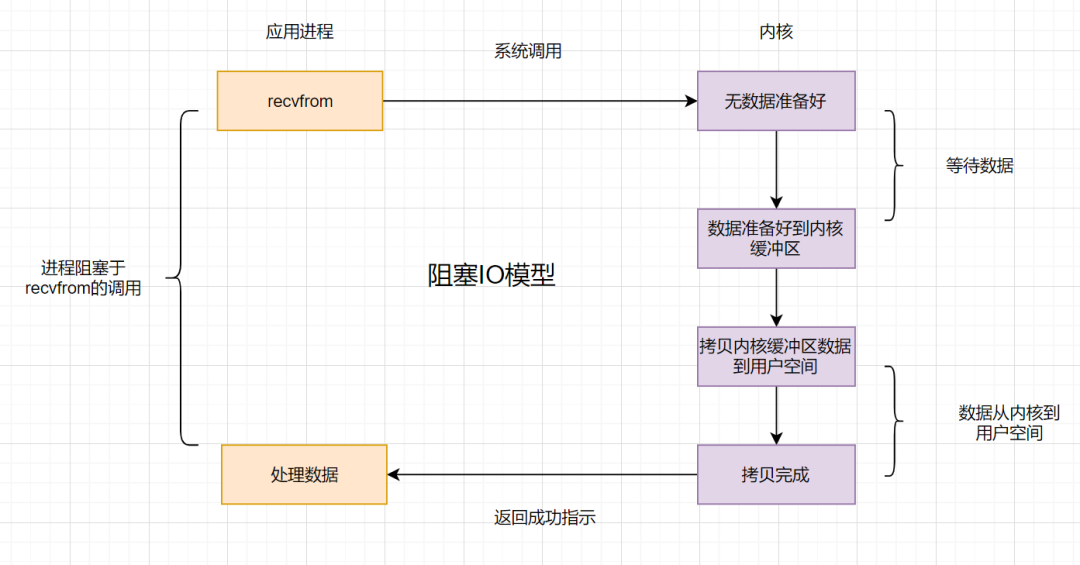
- 阻塞I/O典型:阻塞socket,java BIO
- 缺点:如果内核数据一直没准备好,那用户进程将一直阻塞,浪费性能,可以使用非阻塞IO优化。
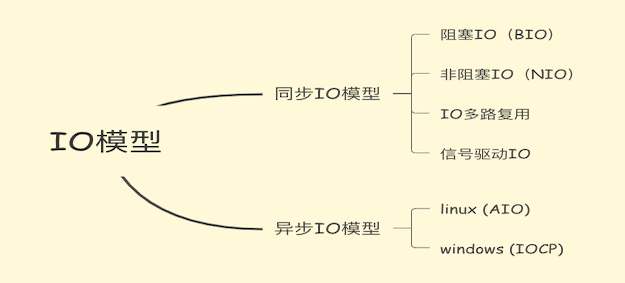
非阻塞I/O 模型
I/O多路复用是一种同步I/O模型,实现一个线程可以监视多个FD(文件句柄);一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作。没有文件句柄就绪时会阻塞应用程序,交出CPU。多路指的是网络链接,复用指的是同一个线程(进程)
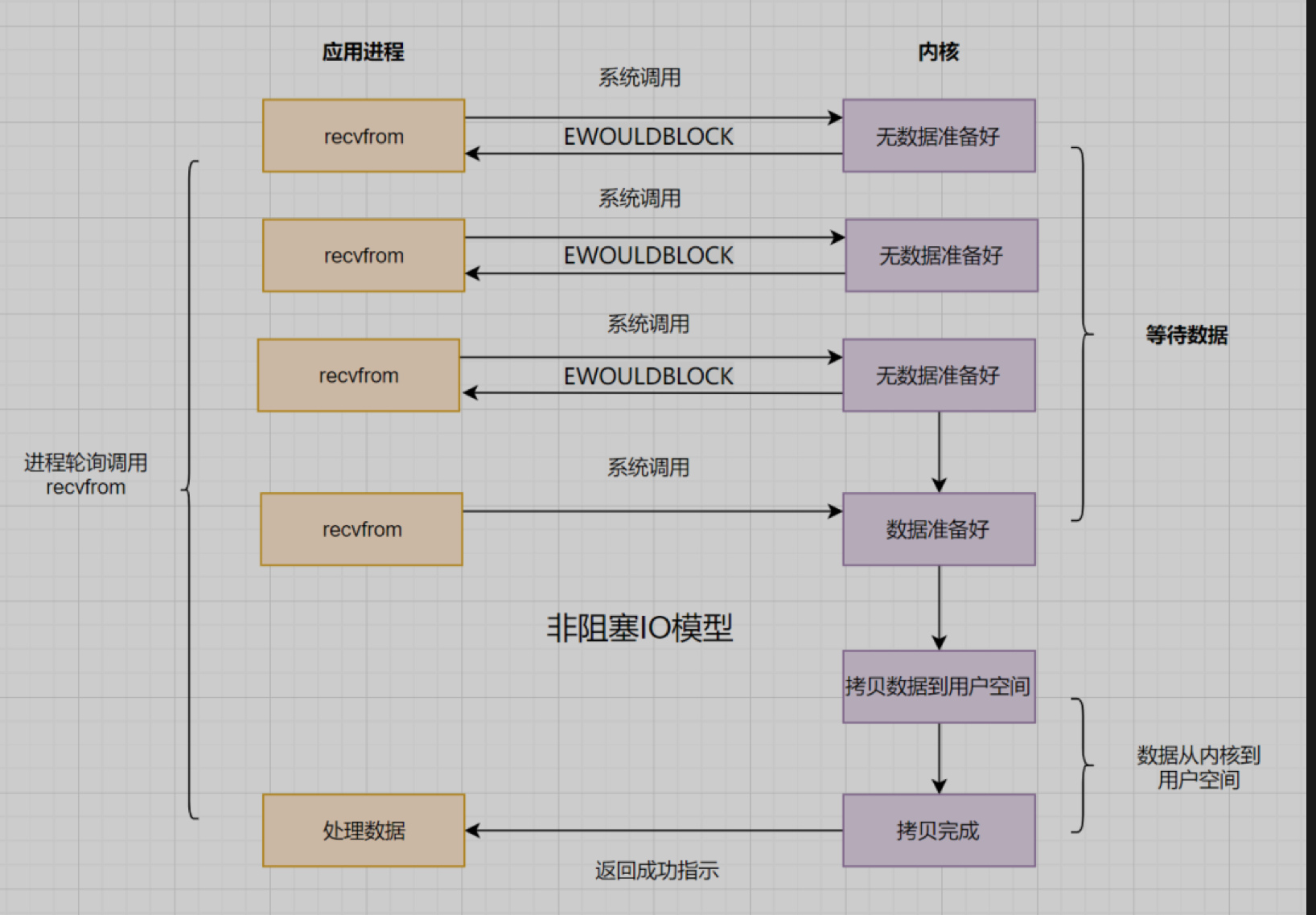
应用进程向操作系统内核,发起recvfrom读取数据。
操作系统内核数据没有准备好,立即返回EWOULDBLOCK错误码。
应用进程轮训调用,继续向操作系统内核发起recvfrom读取数据。
操作系统内核数据准备好了,从内核缓冲区拷贝到用户空间。
完成调用,返回成功。
缺点:非阻塞IO模型,简称NIO,
Non-Blocking IO。它相对于阻塞IO,虽然大幅提升了性能,但是它依然存在性能问题,即频繁的轮询,导致频繁的系统调用,同样会消耗大量的CPU资源。可以考虑IO复用模型,去解决这个问题。
I/O多路复用
NIO利用无效的轮训会导致CPU资源消耗,解决这种无效轮训最好的方式就是通知机制,内核准备好数据后通知用户进程即可。
IO多路复用的核心:操作系统提供了一类函数:select, poll, epll 等同时监控多个fd操作,任何一个返回内核数据就绪,应用进程再发起recvfrom调用。
文件描述符fd(file descriptor)解释:它是计算机科学中的一个术语,形式上是一个非负整数。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。
I/O复用select模式
应用进程通过调用select函数,可以同时监控多个fd,在select函数监控的fd中,只要有任何一个数据状态准备就绪了,select函数都会返回可读状态,这时应用再发起recvfrom调用。
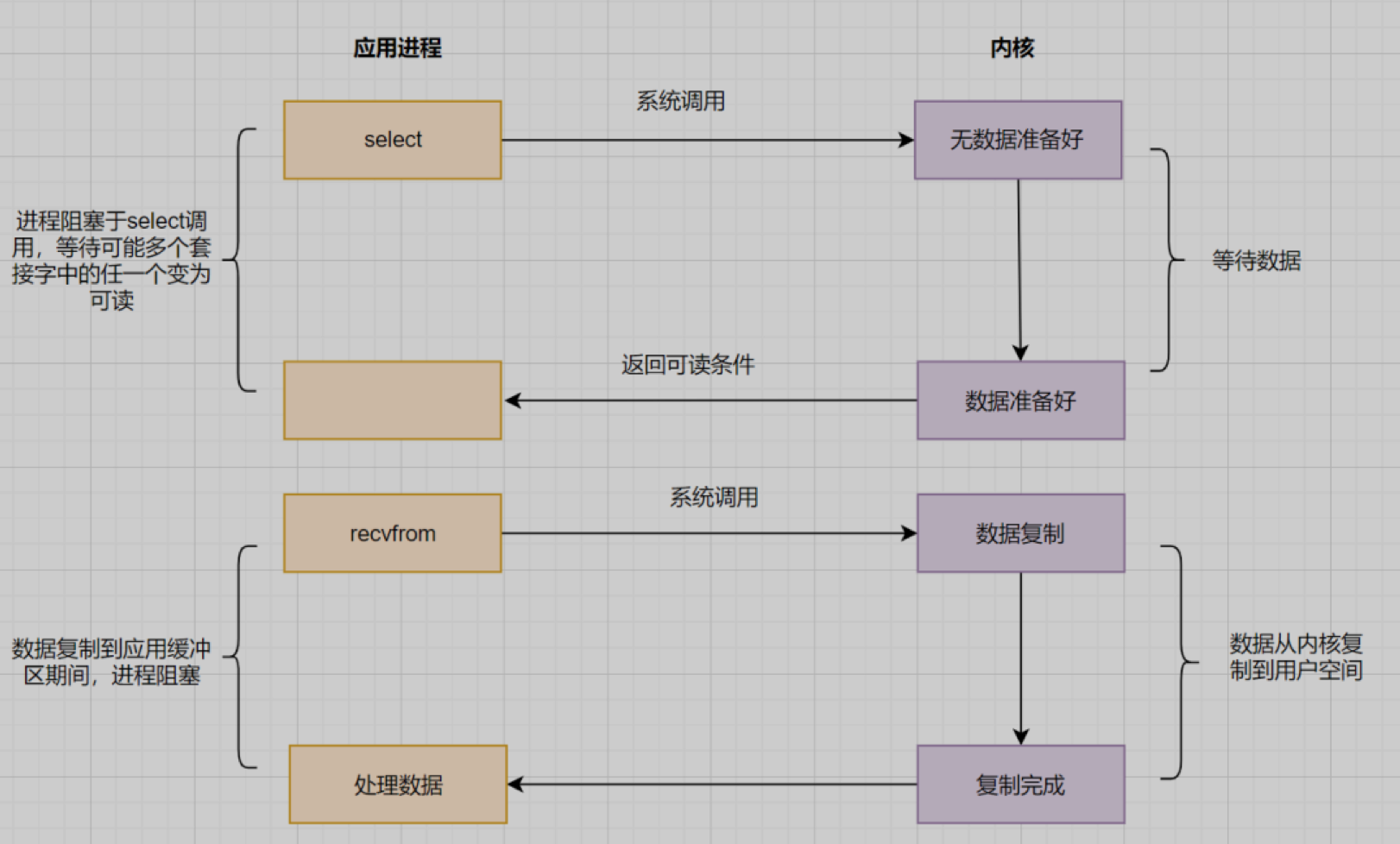
select缺点
- 监听IO最大连接数有限,在Linux系统上一般为1024
- select函数返回后,是通过遍历fdset,找到就绪的fd。(仅仅知道有I/O发生,却不知道哪几个流,所以遍历所有流)
因为存在连接数限制,所以后来又提出了poll。与select相比,poll解决了连接数的问题,但是select和poll一样,还是需要通过文件描述符来获取已经就绪的socket。如果同时连接的大量客户端,在一时刻只有极少数就绪状态,伴随着监视的描述符数量的增长,效率也会线性下降。
I/O多路复用之epoll
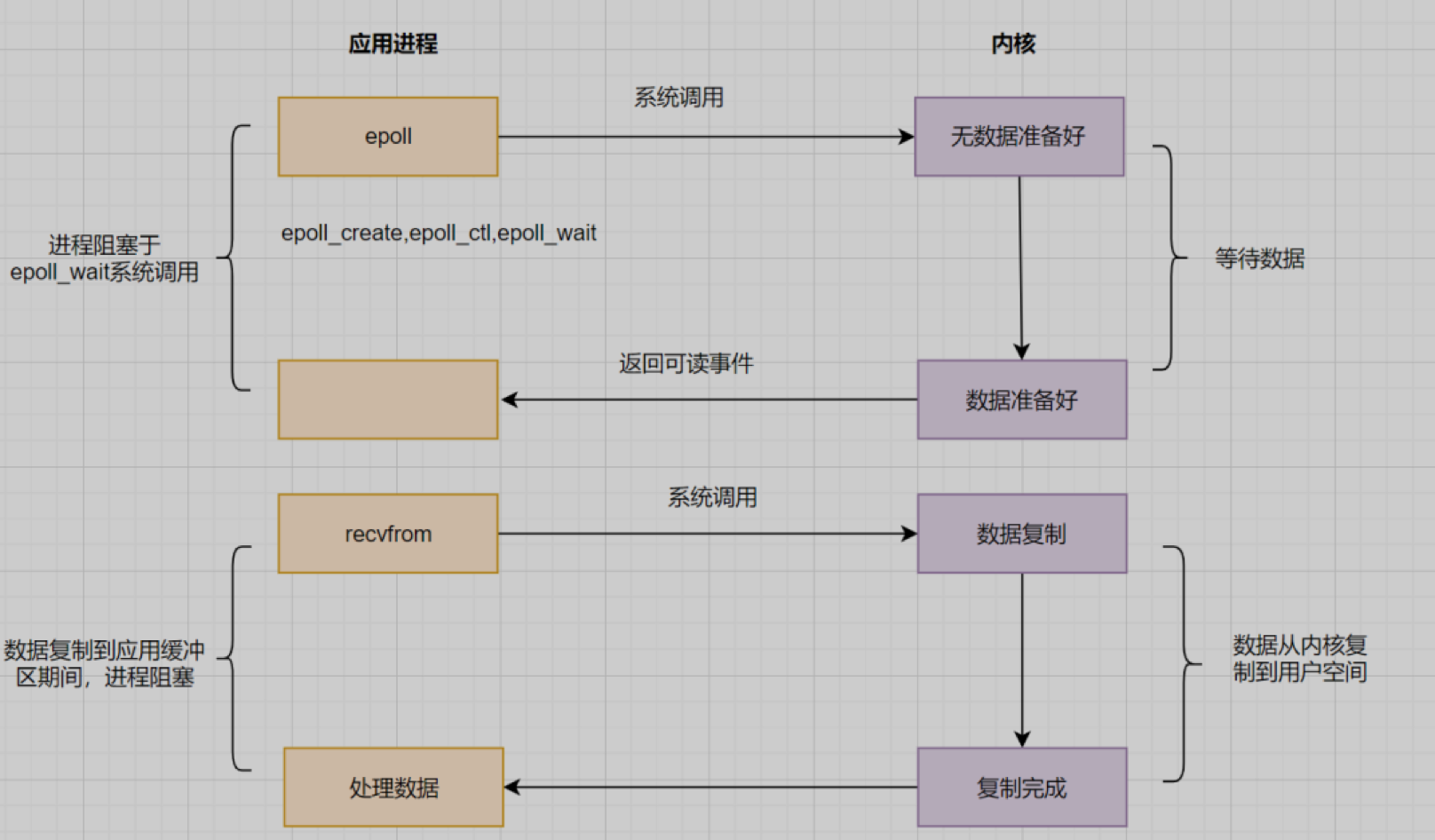
- epoll先通过epoll_ctl()来注册一个fd(文件描述符)
- 当fd就绪时,内核会采用回调机制,迅速激活这个fd,当进程调用epoll_wait()时便得到通知。
select poll epoll区别
| select | poll | Epoll | |
|---|---|---|---|
| 底层数据结构 | 数组 | 链表 | 红黑树和双链表 |
| 获取就绪的fd | 遍历 | 遍历 | 事件回调 |
| 事件复杂度 | O(n) | O(n) | O(1) |
| 最大连接数 | 1024 | 无限制 | 无限制 |
| fd数据拷贝 | 每次调用select,需要将fd数据从用户空间拷贝到内核空间 | 每次调用poll,需要将fd数据从用户空间拷贝到内核空间 | 使用内存映射(mmap),不需要从用户空间频繁拷贝fd数据到内核空间 |
epoll明显优化了IO的执行效率,但在进程调用epoll_wait()时,仍然可能被阻塞。又提出了:等发出请求后,数据准备好通知,这就诞生了信号驱动IO模型。
信号IO驱动模型
信号驱动IO不再用主动询问的方式去确认数据是否就绪,而是向内核发送一个信号(调用signaction的时候建立一个sigio信号),然后应用用户进程可以去做别的事,不用阻塞。当内核数据准备好后,再通过SIGIO信号通知应用进程,数据准备好后的可读状态。应用用户进程收到信号后,立即调用recvfrom,去读取数据。
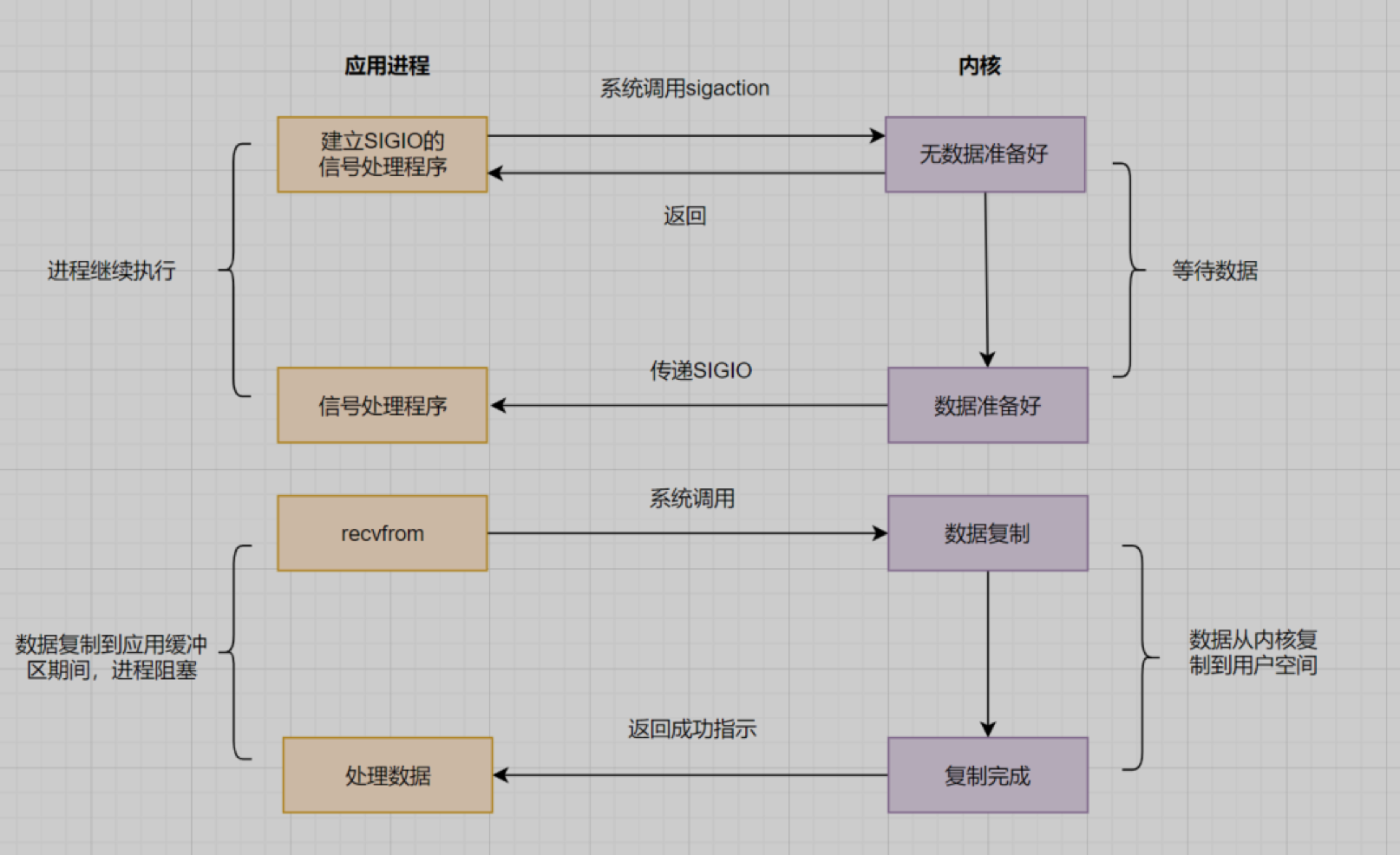
还不是完全的异步IO:数据复制到应用缓冲的时候,应用进程还是阻塞的。
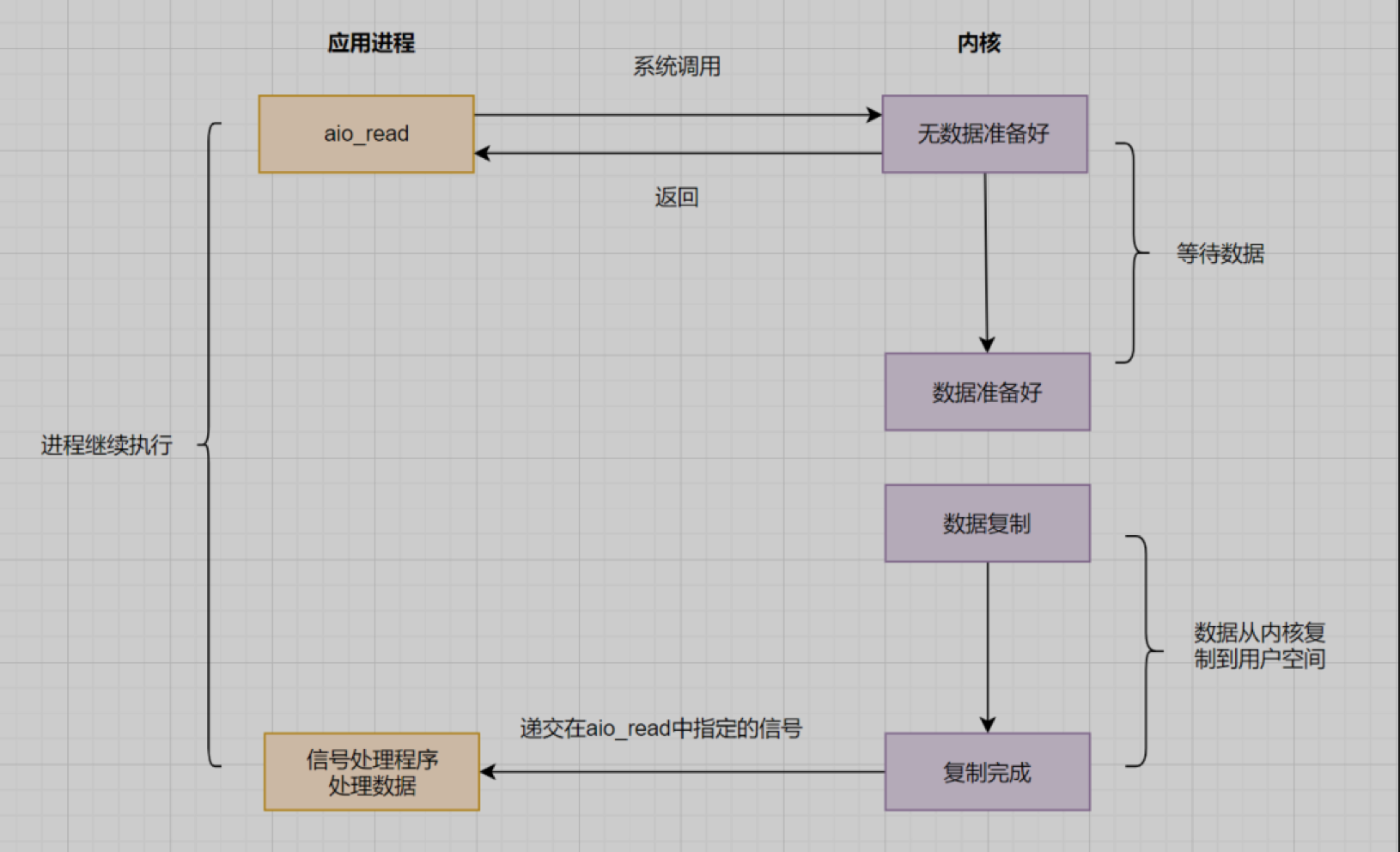
真正的异步IO(AIO)
BIO,NIO和信号驱动,在数据从内核复制到缓冲区的时候都是阻塞的,都不算真正的异步IO。AIO实现了全流程的非阻塞,就是应用进程发出系统调用后,是立即返回的,但是返回的不是处理结果,而是表示提交成功的意思。等到内核数据准备好,将数据拷贝到用户进程缓冲区,发送信号通知用户进程IO操作
阻塞、非阻塞、同步、异步IO划分
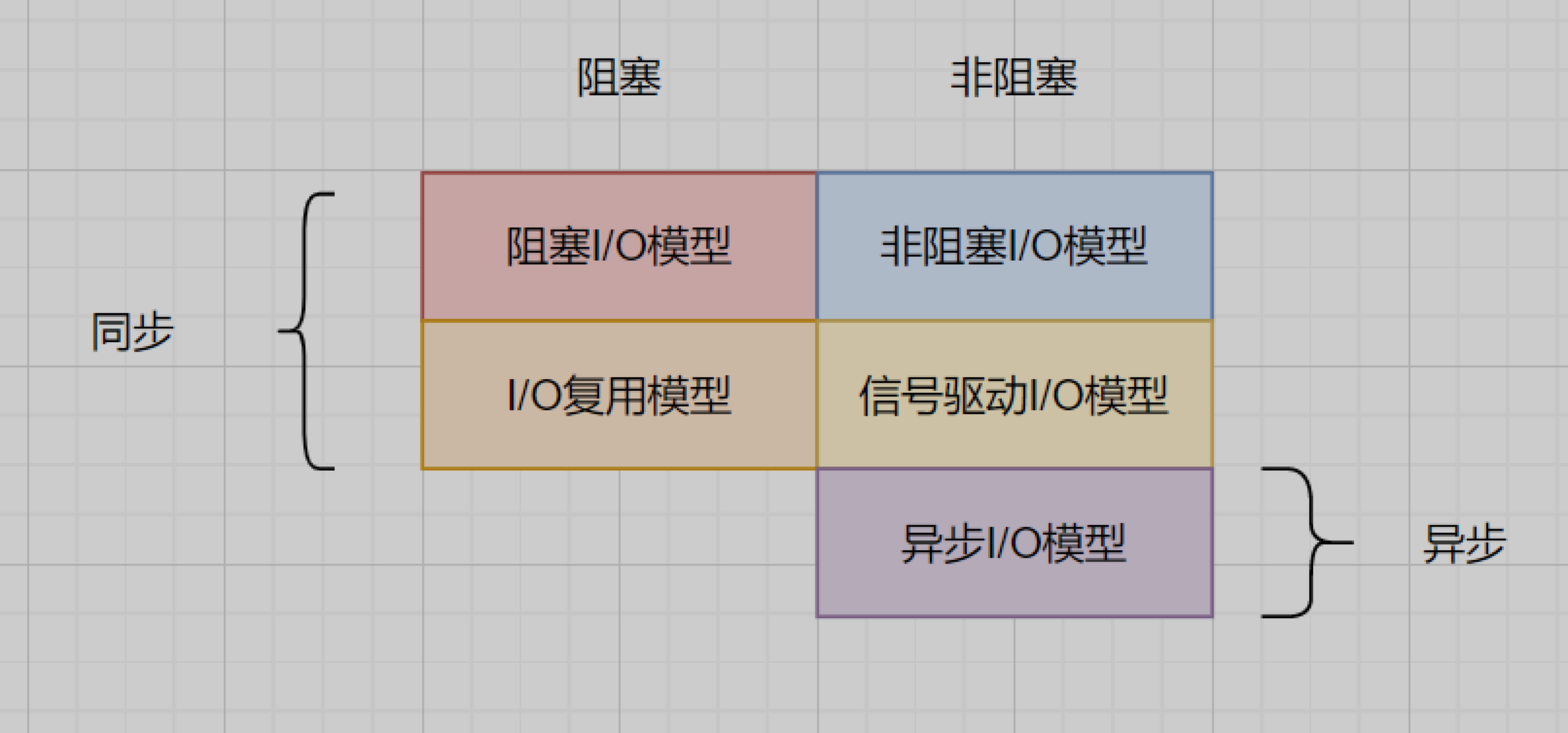
| IO模型 | |
|---|---|
| 阻塞I/O模型 | 同步阻塞 |
| 非阻塞I/O模型 | 同步非阻塞 |
| I/O多路复用模型 | 同步阻塞 |
| 信号驱动I/O模型 | 同步非阻塞 |
| 异步IO(AIO)模型 | 异步非阻塞 |