JTA 原本是 Java EE 中的技术,一般情况下应该由 JBoss、WebSphere、WebLogic 这些 Java EE 容器来提供支持,但现在Bittronix、Atomikos和JBossTM(以前叫 Arjuna)都以 JAR 包的形式实现了 JTA 的接口,也就是 JOTM(Java Open Transaction Manager)。有了 JOTM 的支持,我们就可以在 Tomcat、Jetty 这样的 Java SE 环境下使用 JTA 了。
XA 和 JTA的关系
XA refers to eXtended Architecture, which is a specification for distributed transaction processing. The goal of XA is to provide atomicity in global transactions involving heterogeneous components.
XA specification provides integrity through a protocol known as a two-phase commit. Two-phase commit is a widely-used distributed algorithm to facilitate the decision to commit or rollback a distributed transaction.
Java Transaction API (JTA) is a Java Enterprise Edition API developed under the Java Community Process. It enables Java applications and application servers to perform distributed transactions across XA resources.
JTA is modeled around XA architecture, leveraging two-phase commit. JTA specifies standard Java interfaces between a transaction manager and the other parties in a distributed transaction.
让多个微服务去共享一个数据库这个方案,其实还有另一种应用形式:使用消息队列服务器来代替交易服务器,用户、商家、仓库的服务操作业务时,通过消息将所有对数据库的改动传送到消息队列服务器,然后通过消息的消费者来统一处理,实现由本地事务保障的持久化操作。这就是“单个数据库的消息驱动更新”(Message-Driven Update of a Single Database)。
“共享事务”这种叫法,以及我们刚刚讲到的通过交易服务器或者通过消息驱动来更新单个数据库这两种处理方式,在实际应用中并不常见,也几乎没有相应的成功案例,能够查到的资料几乎都来源于十多年前 Spring 的核心开发者Dave Syer的文章“Distributed Transactions in Spring, with and without XA”。
两段式提交和三段式提交仍然追求 ACID 的强一致性,这个目标不仅给它带来了很高的复杂度,而且吞吐量和使用效果上也不佳。因此,现在系统设计的主流,已经变成了不追求 ACID 而是强调 BASE 的弱一致性事务,这就是我们要在下一讲学习的分布式事务了。
AP : 系统目前是分布式系统设计的主流选择,大多数的 NoSQL 库和支持分布式的缓存都是 AP 系统。因为 P 是分布式网络的天然属性,你不想要也无法丢弃;而 A 通常是建设分布式的目的,如果可用性随着节点数量增加反而降低的话,很多分布式系统可能就没有存在的价值了(除非银行这些涉及到金钱交易的服务,宁可中断也不能出错)。
Ti 与 Ci 满足交换律(Commutative),即不管是先执行 Ti 还是先执行 Ci,效果都是一样的;
Ci 必须能成功提交,即不考虑 Ci 本身提交失败被回滚的情况,如果出现就必须持续重试直至成功,或者要人工介入。
恢复模式
如果 T1 到 Tn 均成功提交,那么事务就可以顺利完成。否则,我们就要采取以下两种恢复策略之一:
正向恢复(Forward Recovery):如果 Ti 事务提交失败,则一直对 Ti 进行重试,直至成功为止(最大努力交付)。这种恢复方式不需要补偿,适用于事务最终都要成功的场景,比如在别人的银行账号中扣了款,就一定要给别人发货。正向恢复的执行模式为:T1,T2,…,Ti(失败),Ti(重试)…,Ti+1,…,Tn。
反向恢复(Backward Recovery):如果 Ti 事务提交失败,则一直执行 Ci 对 Ti 进行补偿,直至成功为止(最大努力交付)。这里要求 Ci 必须(在持续重试后)执行成功。反向恢复的执行模式为:T1,T2,…,Ti(失败),Ci(补偿),…,C2,C1。
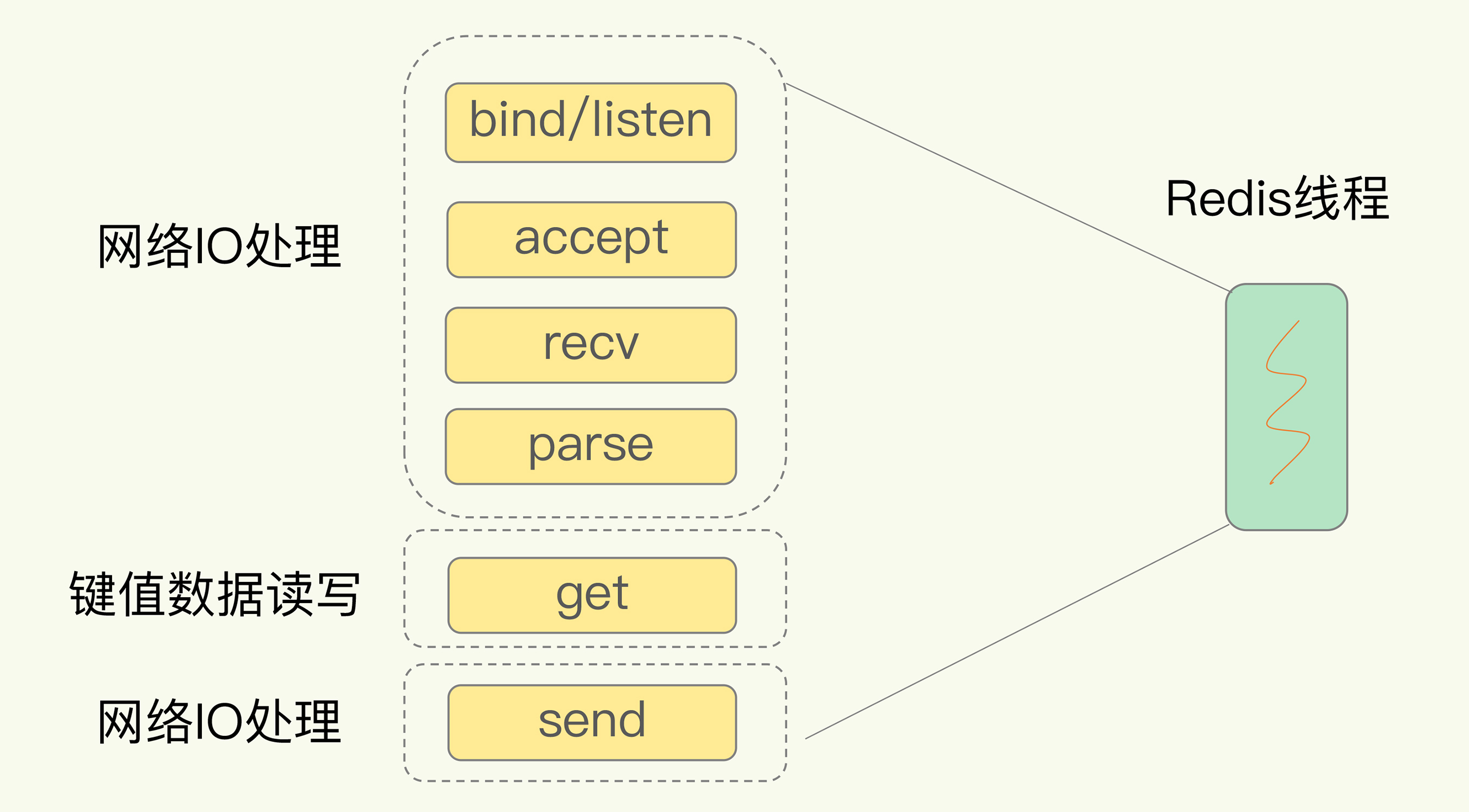
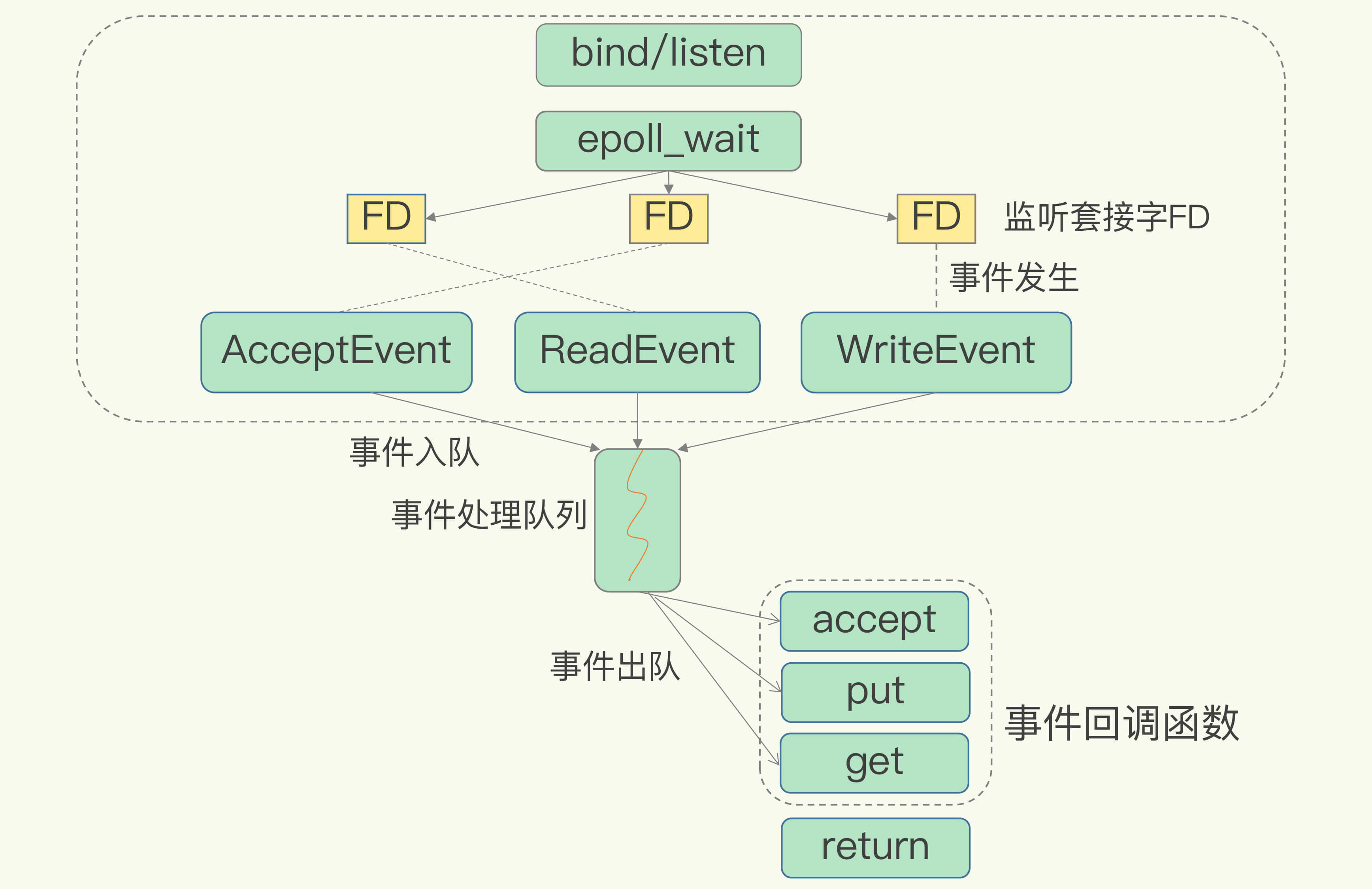
Redis 有 List 的数据类型,并提供出队(LPOP)和入队(LPUSH)操作。假设 Redis 采用多线程设计,如下图所示,现在有两个线程 A 和 B,线程 A 对一个 List 做 LPUSH 操作,并对队列长度加 1。同时,线程 B 对该 List 执行 LPOP 操作,并对队列长度减 1。为了保证队列长度的正确性,Redis 需要让线程 A 和 B 的 LPUSH 和 LPOP 串行执行,这样一来,Redis 可以无误地记录它们对 List 长度的修改。否则,我们可能就会得到错误的长度结果。这就是多线程编程模式面临的共享资源的并发访问控制问题。