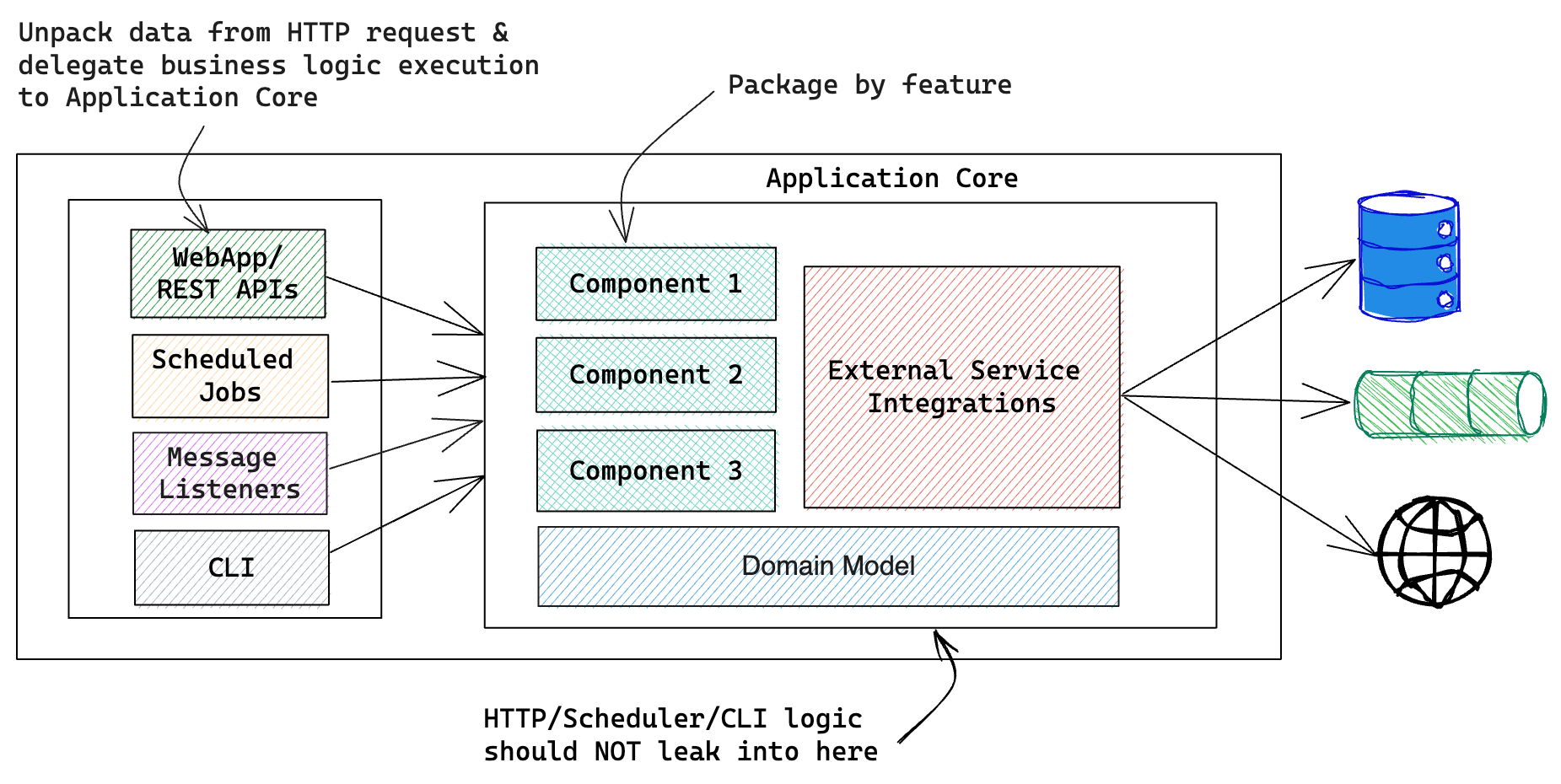
概述 最近20年软件设计发生了天翻地覆的变化,但是SOLID原则至今仍然是软件设计的最佳实践。
SOLID 原则对于对于创建高质量软件是久经测试的标题。但是在现代多范式编程(函数式编程等)和云计算兴起的年代,它依然能够坚挺吗?我将通过如下文章解释SOLID代表了什么,为什么它依然适用现代软件,并且分享一些例子来解释。
什么是SOLID SOLID是Robert C. Martin在2000年提取出来的一系列原则。它被建议去作为面向对象(OO)编程质量的特殊思考方式。总得来讲SOLID在这几个方面:代码如何切分,代码私有和对外暴露,代码之间如何调用提出了建议。我下面将深入研究每个字母(S.O.L.I.D)的原始含义,并且扩展到面向对象编程之外的使用。
有哪些改变? 21世纪早期,是Java和C++称霸的时期,理所当然我的大学很多课程都使用Java语言来当作训练。Java的流行催生出来了一些书籍,课程 和其它资料使得人们从写代码过度到写出好的代码。
因此,软件工业发生了深远的影响。有几个值得注意的点:
**动态类型语言(Dynamically-typed languages) ** 比如 Python,Ruby, 尤其JavaScript 变的和Java一样流行—甚至在某些行业和某类公司已经超过了Java
非面向对象范式(Non-object-oriented paradigms) 最值得注意的是函数式编程(FP),在这些新语言中也比较常见。甚至Java本身也引入了lambdas!元编程技术(增加和改变对象的方法和特性)等技术也越来越流行。还有拥有“软面向对象”特征的Go语言,它具有静态类型但是没有继承。所有的这些都表明了现代软件中类和集成没有过去重要。开源软件(Open-source software) 的扩散。早期,更多的通用软件是闭源(closed-source)人们使用的都是编译后的软件,现在通常人们依赖的软件都是开源的。因此,在编写库是曾经对必不可少的逻辑和数据隐藏不再哪么重要。微服务和软件即服务(Saas) 爆炸式地出现。与其将应用程序部署为将所有依赖项链接在一起的大型可执行文件,不如部署一个与其他服务(自己的活第三方提供支持的服务)调用的小型服务。
整体来看,SOLID真正关心的许多事情——例如类和接口,数据隐藏性和多态——不再是程序员每天都要处理的事情。
有什么没发生变化? 现在工业界有很多不一样了,但是也还有一些东西未发生改变。包括:
代码是由人类编写和修改的 。代码被编写一次并且被读很多很多次。所以对内部和外部需要很好的代码说明文档,尤其很好的API文档。代码被组织成模块 。在某些语言中,这些是类。在其他情况下,他们可能是单独的源文件。在JavaScript中,它们可能是导出对象。无论如何,总是存在某种方式去隔离和组织代码成为独立,有界的单元。因此,总是需要决定如何最好的将代码组织在一起。代码可以是内部的或者外部的 。一些编写出来的代码是被你自己或者你的团队使用,一些可能会被其它团队甚至其他顾客通过API的方式使用。这也意味着需要某种方式来决定哪些代码是“可见的”哪些是隐藏的。
“现代”SOLID 在接下来的文章中,我将把SOLID中的每一项原则都表述为更一般的描述,并且说明是如何应用在OO,FP,多范式编程中的,并距离说明。在许多情况下,这些原则甚至可以应用在整个服务或者系统中。
需要注意的是我将使用“模块”代指一组代码,可以是类,包,文件等等。
单一职责 (Single responsibility principle) 原始定义: “一个类改变的原因不会超过一个”
如果您编写的类有很多关注点或“更改的原因”,那么这些关注点中任何一个需要更改,您就需要更改相同的代码。这增加了对一个特性功能的修改就会破坏另外一个特性功能的可能性。
一个例子,如下是一个永远不应该应用在生产环境的Franken-class:
1 2 3 4 5 6 7 8 9 10 11 12 13 class FrankenClass { public void savaUserDetail (User user) { } public void performOrder (Order order) { } public void shipItem (Item item, String address) { } }
新的定义: “每个模块应该做一件事,并且做好”。
这个原则和高内聚(high cohesion)话题紧密联系。本质上,您的代码不应该将很多角色或者用途混在一起。
如下是使用JavaScript的同一示例的函数式编程(FP)版本:
1 2 3 4 5 const saveUserDetails = (user ) => {...}const performOrder = (order ) => { ...}const shipItem = (item, address ) => { ... }export { saveUserDetails, performOrder, shipItem };import { saveUserDetails, performOrder, shipItem } from "allActions" ;
这也适用在微服务设计;如果你有一个单独服务来处理所有这三个功能,它就会尝试做太多事情。
开闭原则(Open-closed principle) 原始定义: “软件实体应该对扩展开放,对修改关闭。”
这也是Java语言设计的一部分—你可以创建一个子类来继承一个类,但是不能去修改原始的类。
“对扩展开放”的原因之一是限制了对类作者的依赖——如果你需要改动一个类,你不得不去等待类的原始作者去修改,或者你深入研究这个类后再去修改。更重要的是这个类承担了太多的关注点这将打破单一职责原则。
“对修改关闭”的原因是我们不相信下游的使用者能够完全理解我们所有的“private”私有代码,我们希望保护它免收不熟练的人的修改带来的损害。
1 2 3 4 5 6 7 8 9 10 11 12 class Notifier { public void notify (String message) { } } class LoggingNotifier extends Notifier { public void notify (String message) { super .notify(message); } }
新定义: “应该能够在不重写模块的情况下使用和添加模块”。
这在面向对象领域是免费的(AOP)。在函数式编程代码必须明确定义Hook point以允许修改。这事一个示例,其中不仅仅允许使用前后hooks,而且甚至可以通过将函数传递给您的函数来覆盖其基本行为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 const saveRecord = (record, save, beforeSave, afterSave ) => { const defaultSave = (record ) => { } if (beforeSave) beforeSave (record); if (save) { save (record); } else { defaultSave (record); } if (afterSave) afterSave (record); } const customSave = (record ) => {...}saveRecord (myRecord, customSave);
里氏替换原则 原始定义: “如果类型S是T的子类型,那么类型T可以被替换为S类型而不用修改程序的任何所需属性”。
这也是面向对象语言的基础属性。它意味着你可以使用任意子类替换它们的父类。所以你可以对这一个约定充满信心:你可以安全的使用任何 “is a” type T的对象而像T一样去使用。如下例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Vehicle { public int getNumberOfWheels () { return 4 ; } } class Bicycle extends Vehicle { public int getNumberOfWheels () { return 2 ; } } public static int COST_PER_TIRE = 50 ;public int tireCost (Vehicle vehicle) { return COST_PER_TIRE * vehicle.getNumberOfWheels(); } Bicycle bicycle = new Bicycle ();System.out.println(tireCost(bicycle));
新定义: 你可以使用一个东西代替另一个东西只要它们声明的行为方式一样。
在动态语言中,重要的是如果你的程序“promises”去做某些事情(例如实现一个接口或者函数),你需要遵守你的“promises”不要给客户端不符合“promises”的东西。
许多动态语言使用“duck typing”(不知道什么意思 戳这儿 )去达到这一点。本质上,你的function正式或者非正式的声明它期望其输入以特定方式运行并根据该假设运行。
例如Ruby:
1 2 3 4 def split_lines (input ) input.to_s.split("\n" ) end
在这个例子中,这个function并不在乎输入类型——只关心它有一个to_s函数,它的行为方式与所有to_s函数的行为方式相同:即把输入变成字符串。许多动态语言没有办法去强制这种行为,因此这更像一种纪律问题而不是一种形式化技术。
接下来是函数式编程TypeScript例子,在这个例子中高阶函数引入了一个过滤器输入一个数字返回一个boolean值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 const isEven = (x : number ) : boolean =>2 == 0 ;const isOdd = (x : number ) : boolean =>2 == 1 ;const printFiltered = (arr : number [], filterFunc : (int) => boolean arr.forEach ((item ) => { if (filterFunc (item)) { console .log (item); } }) } const array = [1 ,2 ,3 ,4 ,5 ,6 ];printFiltered (array, isEven);printFiltered (array, isOdd);
接口隔离原则(Interface segregation principle) 原始定义: “许多客户端(client-specific)接口要好于一个通用的(general-purpose)接口。”
在面向对象语言中,你可以理解为是为你的类提供了一个“视图”(view)。与其提供给你一个大而全的实现给你的客户端,而是仅使用与该客户端相关的方法在它们之上创建接口,并要求您的客户端使用这些接口。
正如单一职责原则一样,接口隔离原则隔离了系统之间的耦合,并且确保客户端不需要了解它所依赖的无关功能。
如下例子通过SPR测试:
1 2 3 4 5 class PrintRequest { public void createRequest () {} public void deleteRequest () {} public void workOnRequest () {} }
这段代码通常只有一个“原因去更改”——它都与打印请求有关,它们都是同一个域的一部分,并且所有三种方法都可能会更改相同的状态。但是,创建请求的客户端不太可能是处理请求的客户端。将这些接口隔离开会更有意义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 interface PrintRequestModifier { public void createRequest () ; public void deleteRequest () ; } interface PrintRequestWorker { public void workOnRequest () } class PrintRequest implements PrintRequestModifier , PrintRequestWorker { public void createRequest () {} public void deleteRequest () {} public void workOnRequest () {} }
新的定义: “不要向客户端展示它不需要看到的东西。”
只记录你客户端需要知道的内容。这意味着使用文档生成器只输入“public”function 或路由,而“private”没必要输出。
在微服务时代,你可以使用文档或者真正的隔离增加清晰度。例如,你外部客户可能只能以用户身份登录,但你的内部服务可能获取用户列表或者其他属性。你也可以创建一个单独的“仅限外部”用户服务来调用你的主服务,或者你可以只为隐藏内部路由的外部用户输出特定文档。
依赖倒置原则(Dependency inversion principle) 原始定义: “依赖抽象,而不是依赖具体实现”
在面向对象语言中,这意味着客户端应该尽可能依赖接口而不是具体实现类。这确保了代码应该依赖尽可能小的面积——事实上,客户端不必要依赖所有的代码,只需要依赖一个定义代码应该如何表现的契约。和其它原则一样这降低了修改一处而导致破坏了其它功能的风险。下面的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 interface Logger { public void write (String message) ; } class FileLogger implements Logger { public void write (String message) { } } class StandardOutLogger implements Logger { public void write (String message) { } } public void doStuff (Logger logger) { logger.write("some message" ); }
如果你正在写的代码需要一个logger, 你不想去限制自己仅仅只是去写入文件中,因为你不在乎。你仅仅只需要调用 write方法而让具体实现去输出。
新的定义: “依赖抽象,而不是具体实现。”
对的,这个例子我将定义保留原样!保持东西依赖抽象依然是重要的,即使现代代码中的抽象机制不像严格的面向对象世界那样强大。
尤其,这和上面讨论的里氏替换原则是一样的。主要的区别是它没有默认实现。因此,该部分中涉及鸭子类型和钩子函数的讨论通用适用于依赖倒置。
你也可以使用抽象对于微服务。比如,你可以将服务之间的直接通信替换为消息总线活队列平台,例如Kafka或者其他消息中间件。这样允许服务将消息发送到单个通用位置,而无需关心哪个特定服务将接收这些消息并执行其任务。
总结 再次重新梳理“现代SOLID”一次:
不要惊讶别人读到你的代码。
不要惊讶别人使用你的代码。
不要让阅读你代码的人感到迷惑。
为你的代码使用合理的边界。
使用正确的耦合级别——尘归尘,土归土。
好的代码就是好的代码——从未改变,SOLID也是,实践是坚实的基础。
原文连接: https://stackoverflow.blog/2021/11/01/why-solid-principles-are-still-the-foundation-for-modern-software-architecture/?utm_source=programmingdigest&utm_medium=web&utm_campaign=447
Comment and share