Java创建对象的5种方式
| 创建方式 | 原理 |
|---|---|
| new关键字 | 通过调用构造器 |
| 反射 | (同 new 关键字) |
| Object.clone | 通过复制已有数据,来初始化新建对象实例 |
| 反序列化 | (同 Object.clone) |
| Unsafe.allocateInstance | 没有初始化实例字段 |
Java对构造器的约束:
- 如果一个类没有任何构造器的话,会自动添加一个无参构造器。
- 子类的构造器需要调用父类的构造器。如果父类存在无参数构造器的话,该调用可以是隐式的,也就是说 Java 编译器会自动添加对父类构造器的调用。但是,如果父类没有无参数构造器,那么子类的构造器则需要显式地调用父类带参数的构造器。
- 显式调用又可分为两种,一是直接使用“super”关键字调用父类构造器,二是使用“this”关键字调用同一个类中的其他构造器。无论是直接的显式调用,还是间接的显式调用,都需要作为构造器的第一条语句,以便优先初始化继承而来的父类字段。(不过这可以通过调用其他生成参数的方法,或者字节码注入来绕开。)
- 通过 new 指令新建出来的对象,它的内存其实涵盖了所有父类中的实例字段。也就是说,虽然子类无法访问父类的私有实例字段,或者子类的实例字段隐藏了父类的同名实例字段,但是子类的实例还是会为这些父类实例字段分配内存的。
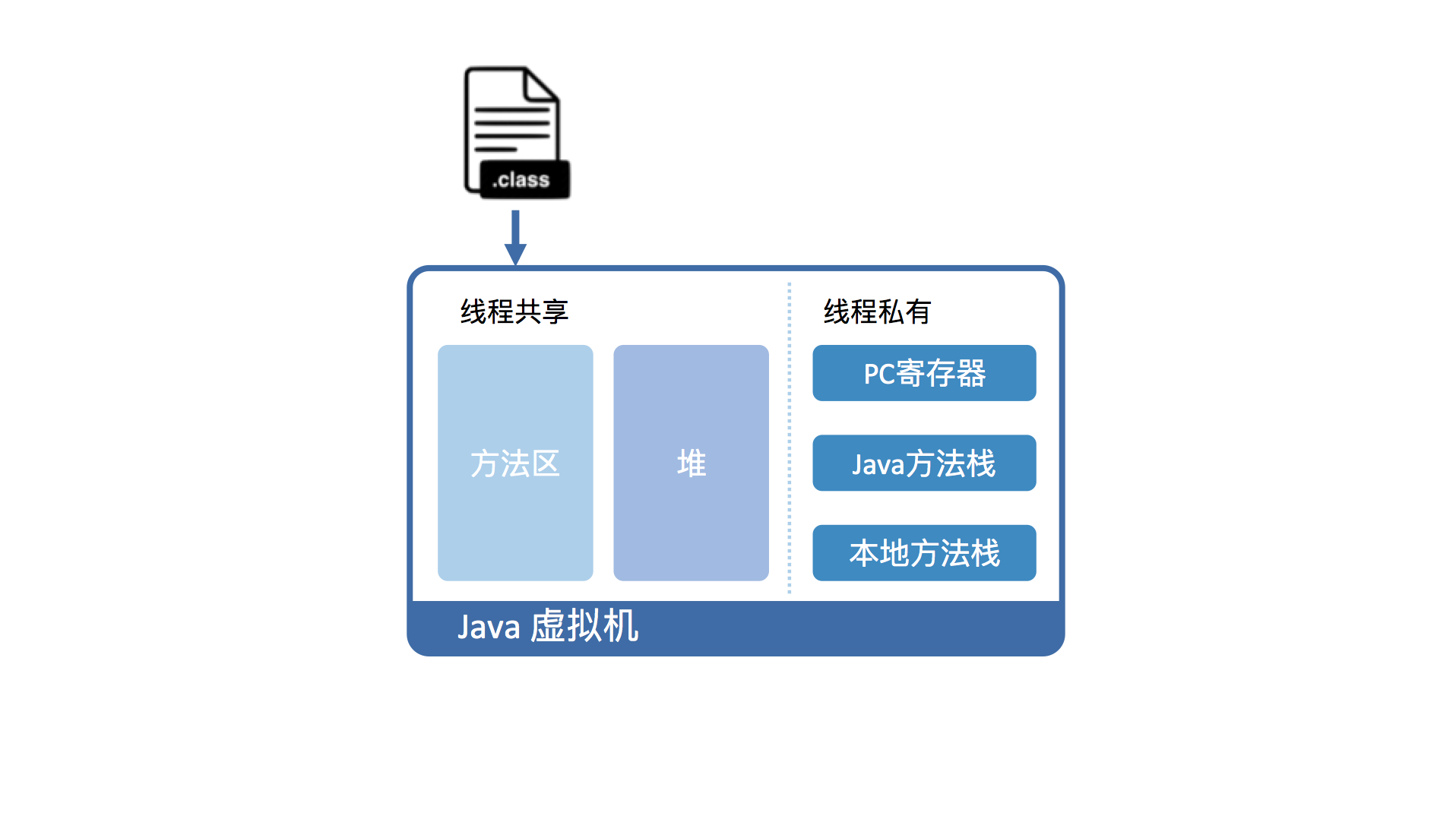
对象内存占用分布
每个对象都有一个对象头(Object header)
由标记字段(Mark Word)和类型指针所构成。其中:mark word用以存储Java虚拟机有关该对象的运行数据:hash码,GC信息以及锁信息,而类型指针则是指向该对象的类。
1
2
3
4
5|--------------------------------------------------------------|
| Object Header (128 bits) |
|------------------------------------|-------------------------|
| Mark Word (64 bits) | Klass pointer (64 bits) |
|------------------------------------|-------------------------|为了尽量较少对象的内存使用量,64位Java虚拟机引入压缩指针(-XX: +UseCompressedOops,默认开启),将Java对象指针压缩成为32位。
1
2
3
4
5|--------------------------------------------------------------|
| Object Header (96 bits) |
|------------------------------------|-------------------------|
| Mark Word (64 bits) | Klass pointer (32 bits) |
|------------------------------------|-------------------------|数组对象
1
2
3
4
5|---------------------------------------------------------------------------------|
| Object Header (128 bits) |
|--------------------------------|-----------------------|------------------------|
| Mark Word(64bits) | Klass pointer(32bits) | array length(32bits) |
|--------------------------------|-----------------------|------------------------|
压缩指针
将堆中原本 64 位的 Java 对象指针压缩成 32 位的。
原理:
默认情况下,Java 虚拟机堆中对象的起始地址需要对齐至 8 的倍数(内存对齐-XX:ObjectAlignmentInBytes,默认值为 8)。如果一个对象用不到 8N 个字节,那么空白的那部分空间就浪费掉了。这些浪费掉的空间我们称之为对象间的填充(padding)。
就算是关闭了压缩指针,Java 虚拟机还是会进行内存对齐。此外,内存对齐不仅存在于对象与对象之间,也存在于对象中的字段之间。比如说,Java 虚拟机要求 long 字段、double 字段,以及非压缩指针状态下的引用字段地址为 8 的倍数。
字段内存对齐的其中一个原因,是让字段只出现在同一 CPU 的缓存行中。如果字段不是对齐的,那么就有可能出现跨缓存行的字段。也就是说,该字段的读取可能需要替换两个缓存行,而该字段的存储也会同时污染两个缓存行。这两种情况对程序的执行效率而言都是不利的。
字段重排列
字段重排列,顾名思义,就是 Java 虚拟机重新分配字段的先后顺序,以达到内存对齐的目的。Java 虚拟机中有三种排列方法(对应 Java 虚拟机选项 -XX:FieldsAllocationStyle,默认值为 1)
如果一个字段占据 C 个字节,那么该字段的偏移量需要对齐至 NC。
这里偏移量指的是字段地址与对象的起始地址差值。以 long 类为例,它仅有一个 long 类型的实例字段。在使用了压缩指针的 64 位虚拟机中,尽管对象头的大小为 12 个字节,该 long 类型字段的偏移量也只能是 16,而中间空着的 4 个字节便会被浪费掉。
子类所继承字段的偏移量,需要与父类对应字段的偏移量保持一致。
在具体实现中,Java 虚拟机还会对齐子类字段的起始位置。对于使用了压缩指针的 64 位虚拟机,子类第一个字段需要对齐至 4N;而对于关闭了压缩指针的 64 位虚拟机,子类第一个字段则需要对齐至 8N。
Java 8 还引入了一个新的注释 @Contended,用来解决对象字段之间的虚共享(false sharing)问题。这个注释也会影响到字段的排列。虚共享是怎么回事呢?
假设两个线程分别访问同一对象中不同的 volatile 字段,逻辑上它们并没有共享内容,因此不需要同步。然而,如果这两个字段恰好在同一个缓存行中,那么对这些字段的写操作会导致缓存行的写回,也就造成了实质上的共享。Java 虚拟机会让不同的 @Contended 字段处于独立的缓存行中,因此你会看到大量的空间被浪费掉。具体的分布算法属于实现细节,注意使用虚拟机选项 -XX:-RestrictContended。如果你在 Java 9 以上版本试验的话,在使用 javac 编译时需要添加 –add-exports java.base/jdk.internal.vm.annotation=ALL-UNNAME